LightGBM算法原理
在 XGBoost介绍中,我们讲述了xgb的运行原理,节点分裂方式。在xgb出现之后,迅速的应用在工业界中并取得了非常好的效果。但是仍然存在一些问题,比如当数据规模巨大的情况下,运行速度慢,不能直接支持类别特征等。在2017年,微软发布了一个新的GBDT算法框架LightGBM,与xgb相比,达到相同的算法效果,运行速度更快,并且支持类别特征。lgb的主要改进点是提升模型速度,从两个维度进行了优化,分别是样本维度和特征维度。本文基于lgb的论文进行总结归纳,以便时常温习回顾。
一、主要改进点
- 直方图算法(histogram-based algorithm):基于连续特征值进行分桶bin,然后基于不同的bin进行分裂。相比于预排序算法,节省内存和提升速度。
- 单边梯度采样算法GOSS(Gradient-based One-Side Sampling):计算增益过程中,不再使用全部样本,而是筛选出一部分梯度大的样本和部分梯度小的样本计算增益。减少样本数量,提升计算速度。
- 互斥特征绑定算法EFB(Exclusive Feature Bundling):在高维稀疏特征中,部分特征并不会同时非零,所以可以将其中几个特征绑定为一个特征,进行分裂。减少特征数量,提升计算速度。
- 叶子节点生长策略(leaf-wise tree growth strategy):xgb在树的生成过程中,每次都是一层的所有节点都进行分裂,lgb是每次选择所有叶节点中收益最大的节点分裂,有利有弊,利:降低模型误差,弊:树生长过深,可能会过拟合。
二、直方图算法
寻找最佳分割点,如何才能更高效?这就是直方图算法要解决的问题。GBDT算法是基于决策树的ensemble模型,树的每次生长都是要寻找分割点,将数据分到左子树和右子树中,如何寻找这个分割点是非常耗时的。一种是预排序算法,即将特征f的所有取值从小到大排序,然后遍历每一个特征取值\(f_{i}\),分别以\(f_{i}\)为分割点,计算增益,选取最大的增益对应的分割点作为当前的分割节点。一种方法是直方图算法,即将连续特征离散化,分到指定的几个bin内,比如特征取值1-10分到bin=1内,10-20分到bin=2内....。寻找最佳分割点时直接根据bin的取值来分割即可。二者相比时间复杂度分别为O(datafeature)和O(binfenture),feature表示特征维度,data表示样本数量,bin表示桶数量。

上图就是直方图算法的主题逻辑。
三、GOSS采样策略
GOSS采样策略的灵感来自于Adaboost,在adaboost中,样本是有权重的,样本的误差越大,权重越高,在下次训练时模型会更加关注误差更大的样本。但是在GBDT算法中样本是没有权重的,无法直接将Adaboost的方式迁移过来。但是在GBDT算法中,样本的梯度越小,则误差越小,表示该样本被训练的更好,所以误差和梯度之间也是有一定关系的。因此是否可以考虑将这部分训练的很好地样本丢掉,但是直接丢掉样本会影响分布。所以LightGBM提出依据样本梯度进行采样的策略。思路很简单,
按照样本梯度绝对值从大到小排序
选取topa%梯度较大的样本,然后再选取b%梯度较小的样本(b是指全部样本的b%)
对采样出来的小梯度样本乘以(1-a)/b,提升小梯度样本的权重(1-a是表示小梯度样本的分布,大梯度样本的分布是a,1/b是将小梯度样本的比例放大b倍)。

上图是GOSS算法的整体逻辑。
四、互斥特征绑定算法
互斥特征绑定的目的是降低特征维度,减少计算量,其实也有点类似于列采样。在高维稀疏特征中,很多特征并不会同时非零。即多个特征可以合并成一维特征,LightGBM采用了互斥特征绑定算法(EFB)来降低特征维数。将特征进行分桶,桶内特征是互斥的,然后将桶内特征合并成一个特征再去进行分裂。这样可以将数据从O(datafeature)降低到O(databuddle)。该方法实现起来存在两大难点:
- 哪些特征可以放在一起
- 如何构建buddle
4.1哪些特征可以绑定
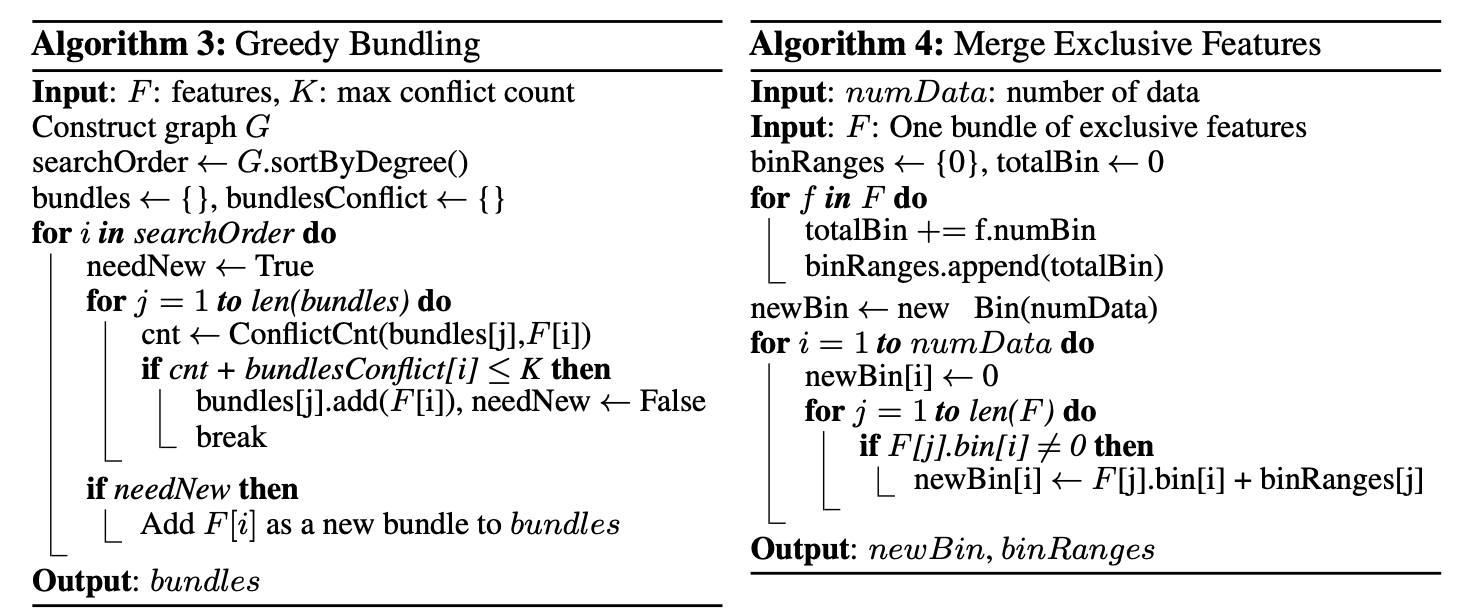
对于第一个问题,EFB算法是构建了一个图G=(V,E),图的顶点E是特征,顶点之间的边V表示特征之间的冲突数,将存在冲突的两个顶点构建一条边。然后将不存在冲突的顶点放到一个集合内,构成一个特征包。在LightGBM中,为了提升效率,它是允许一部分特征之间存在一定的冲突的,即允许存在\(gamma\)个冲突。通过控制\(gamma\)的大小,可以让算法精度和效率有一定的平衡。算法思路为:
- 构建加权图,V表示两个特征之间的冲突数
- 将特征按照冲突数降序排列,分配特征到不同的特征包内
- 通过控制特征包内最大冲突数K来决定该特征是放入已有特征包内还是新建特征包
- 这样算法思路为O(feature*feature),因为要两两遍历特征之间的冲突
这样做对于特征维度较小时还可以完成,维度一旦百万级就无法承受了。
因此为了简化上述计算特征冲突数的过程,采样一个特征下非0的样本数量,一个特征下非0值特征越多,则越容易冲突。
4.2如何构建buddle
上面解决了如何判断哪些特征要被绑定在一起,那么EFB算法如何绑定特征呢?如何既减少了特征维度,又保证原始的特征值可以在特征包中被识别出来呢?由于LightGBM是采用直方图算法减少对于寻找最佳分裂点的算法复杂度,直方图算法将特征值离散到若干个bin中。这里EFB算法为了保留特征,将bundle内不同的特征加上一个偏移常量,使不同特征的值分布到bundle的不同bin内。例如:特征A的取值范围为[0,10),特征B的原始取值范围为[0,20),对特征B的取值上加一个偏置常量10,将其取值范围变为[10,30),这样就可以将特征A和B绑定在一起了。具体的算法流程上图Algorithm4所示。
五、按叶子生长(leaf-wise)
在xgb中,决策树的构建是按照层生长的。每次都是把一层的节点都进行分裂,这种操作复杂度会高,而且一层中未必所有节点都有很高的收益。所以在LightGBM中是按照叶子节点生长的,每次选择所有叶子节点中收益最大的那个节点进行分裂,依次循环下去。和xgb相比,优点是lgb减少了一部分收益较小的节点分裂开销,生成的树较深,更容易降低误差,缺点是树较深,有可能会过拟合,所以lgb有一个控制树的深度的参数,防止过拟合。
六、并行优化
Feature Parallel 特征并行算法目的是在决策树生成过程中的每次迭代,高效地找到最优特征分裂点。特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
传统的特征并行算法
根据不同的特征子集,将数据集进行垂直切分。(不同机器worker有不同的特征子集) 每个worker寻找局部的最优分裂特征以及分裂点。 不同worker之间进行网络传输,交换最优分裂信息,最终得到最优的分裂信息。 具有最优分裂特征的worker,局部进行分裂,并将分裂结果广播到其他worker。 其他worker根据接收到的数据进行切分数据。 该方法不能有效地加速特征选择的效率,当数据量#data很大时,该并行方法不能加快效率。并且,最优的分裂结果需要在worker之间进行传输,需要消耗很多的传输资源以及传输时间。
LightGBM的特征并行算法 LightGBM并没有垂直的切分数据集,而是每个worker都有全量的训练数据,因此最优的特征分裂结果不需要传输到其他worker中,只需要将最优特征以及分裂点告诉其他worker,worker随后本地自己进行处理。处理过程如下:
每个worker在基于局部的特征集合找到最优分裂特征。 workder间传输最优分裂信息,并得到全局最优分裂信息。 每个worker基于全局最优分裂信息,在本地进行数据分裂,生成决策树。 然而,当数据量很大时,特征并行算法还是受限于特征分裂效率。因此,当数据量大时,推荐使用数据并行算法。
Data Parallel 传统的数据并行算法
水平切分数据集。 每个worker基于数据集构建局部特征直方图(Histogram)。 归并所有局部的特征直方图,得到全局直方图。 找到最优分裂信息,进行数据分裂。 缺点:网络传输代价比较大,如果使用point-to-point的传输算法,每个worker的传输代价为\(O(#machine * #feature * #bin)\). 如果使用All Reduce并行算子,传输代价为\(O(2* #feature * #bin)\).
LightGBM的数据并行算法 LightGBM算法使用Reduce Scatter并行算子归并来自不同worker的不同特征子集的直方图,然后在局部归并的直方图中找到最优局部分裂信息,最终同步找到最优的分裂信息。 除此之外,LightGBM使用直方图减法加快训练速度。我们只需要对其中一个子节点进行数据传输,另一个子节点可以通过histogram subtraction得到。 LightGBM可以将传输代价降低为\(O(0.5 * #feature * #bin)\)。
六、总结
lgb效率更高主要得益于它的几个优化点,
- 分裂的时候采用直方图算法,相当于减少计算的样本数
- 计算增益的时候的采用GOSS算法,对样本采样,也是减少样本数
- 对于高维稀疏特征采用EFB算法,相当于降低特征维度
- 树的生长采用按叶子生长,减少不必要的计算开销
万变不离其宗,主题核心就是减少样本数或者减少特征数两个点展开,结果也验证了作者的想法。
Ref:
https://zhuanlan.zhihu.com/p/59631419
http://www.csuldw.com/2019/07/24/2019-07-24-an-introduction-tolightGBM-explained/
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!